Big data is a term that describes the large volume of data – both structured and unstructured – that inundates a business on a day-to-day basis. But it’s not the amount of data that’s important. It’s what organizations do with the data that matters. Big data can be analyzed for insights that lead to better decisions and strategic business moves.
While the term “big data” is relatively new, the act of gathering and storing large amounts of information for eventual analysis is ages old. The concept gained momentum in the early 2000s when industry analyst Doug Laney articulated the now-mainstream definition of big data as the three Vs:
Volume. Organizations collect data from a variety of sources, including business transactions, social media and information from sensor or machine-to-machine data. In the past, storing it would’ve been a problem – but new technologies (such as Hadoop) have eased the burden.
Velocity. Data streams in at an unprecedented speed and must be dealt with in a timely manner. RFID tags, sensors and smart metering are driving the need to deal with torrents of data in near-real time.
Variety. Data comes in all types of formats – from structured, numeric data in traditional databases to unstructured text documents, email, video, audio, stock ticker data and financial transactions.
At SAS, we consider two additional dimensions when it comes to big data:
Variability. In addition to the increasing velocities and varieties of data, data flows can be highly inconsistent with periodic peaks. Is something trending in social media? Daily, seasonal and event-triggered peak data loads can be challenging to manage. Even more so with unstructured data.
Why Is Big Data Important?
The importance of big data doesn’t revolve around how much data you have, but what you do with it. You can take data from any source and analyze it to find answers that enable 1) cost reductions, 2) time reductions, 3) new product development and optimized offerings, and 4) smart decision making. When you combine big data with high-powered analytics, you can accomplish business-related tasks such as:
- Determining root causes of failures, issues and defects in near-real time.
- Generating coupons at the point of sale based on the customer’s buying habits.
- Recalculating entire risk portfolios in minutes.
- Detecting fraudulent behavior before it affects your organization.
Relational database management system
A relational database management system (RDBMS) is a database management system (DBMS) that is based on the relational model as invented by E. F. Codd, of IBM's San Jose Research Laboratory. In 2016, many of the databases in widespread use are based on the relational database model.
RDBMSs have been a common choice for the storage of information in new databases used for financial records, manufacturing and logistical information, personnel data, and other applications since the 1980s. Relational databases have often replaced legacy hierarchical databases and network databases because they are easier to understand and use. However, relational databases have received unsuccessful challenge attempts by object database management systems in the 1980s and 1990s (which were introduced trying to address the so-called object-relational impedance mismatch between relational databases and object-oriented application programs) and also by XML database management systems in the 1990s.[citation needed] Despite such attempts, RDBMSs keep most of the market share, which has also grown over the years.
According to DB-Engines, in 2016, the most widely used systems are Oracle, MySQL (open source), Microsoft SQL Server, PostgreSQL (open source), IBM DB2, Microsoft Access, and SQLite (open source).[1]
According to research company Gartner, in 2011, the five leading commercial relational database vendors by revenue were Oracle (48.8%), IBM (20.2%), Microsoft (17.0%), SAP including Sybase (4.6%), and Teradata (3.7%).[2]
According to Gartner, in 2008, the percentage of database sites using any given technology were (a given site may deploy multiple technologies):[3]
- Oracle Database – 70%
- Microsoft SQL Server – 68%
- MySQL (Oracle Corporation) – 50%
- IBM DB2 – 39%
- IBM Informix – 18%
- SAP Sybase Adaptive Server Enterprise – 15%
- SAP Sybase IQ – 14%
- Teradata – 11
Database Management System vs. Relational Database Management System:
The below table lists downs some of the major differences between DBMS and RDBMS.
| Sl.# | DBMS | RDBMS |
|---|---|---|
| 1 | Introduced in 1960s. | Introduced in 1970s. |
| 2 | During introduction it followed the navigational modes (Navigational DBMS) for data storage and fetching. | This model uses relationship between tables using primary keys, foreign keys and indexes. |
| 3 | Data fetching is slower for complex and large amount of data. | Comparatively faster because of its relational model. |
| 4 | Used for applications using small amount of data. | Used for huge applications using complex and large amount of data. |
| 5 | Data Redundancy is common in this model leading to difficulty in maintaining the data. | Keys and indexes are used in the tables to avoid redundancy. |
| 6 | Example systems are dBase, Microsoft Acces, LibreOffice Base, FoxPro. | Example systems are SQL Server, Oracle , MySQL, MariaDB, SQLite. |
A List of Relational Database Management System Examples
List of top 10 relational database management system example.If relation between object is defined in the form of table then its called Relational Database management systems. Here is top 10 examples of Relational database management systems.
- Oracle
- MySQL
- Microsoft SQL server
- PostgreSQL
- DB2
- Microsoft access
- Sq Lite
- Sybase
- Tera data
- Fire bird
http://technicgang.com/relational-database-management-system-examples/
http://www.mytecbits.com/microsoft/sql-server/what-is-dbms-what-is-rdbms
https://en.wikipedia.org/wiki/Relational_database_management_system
Different Types of Databases
here are different types of databases which are categorised on the basis of their function. The top 12 of these which you may come across are:
1.0 Relational Databases
This is the most common of all the different types of databases. In this, the data in a relational database is stored in various data tables. Each table has a key field which is used to connect it to other tables. Hence all the tables are related to each other through several key fields. These databases are extensively used in various industries and will be the one you are most likely to come across when working in IT.
Examples of relational databases are Oracle, Sybase and Microsoft SQL Server and they are often key parts of the process of software development. Hence you should ensure you include any work required on the database as part of your project when creating a project plan and estimating project costs.
2.0 Operational Databases
In its day to day operation, an organisation generates a huge amount of data. Think of things such as inventory management, purchases, transactions and financials. All this data is collected in a database which is often known by several names such as operational/ production database, subject-area database (SADB) or transaction databases.
An operational database is usually hugely important to Organisations as they include the customer database, personal database and inventory database ie the details of how much of a product the company has as well as information on the customers who buy them. The data stored in operational databases can be changed and manipulated depending on what the company requires.
3.0 Database Warehouses
Organisations are required to keep all relevant data for several years. In the UK it can be as long as 6 years. This data is also an important source of information for analysing and comparing the current year data with that of the past years which also makes it easier to determine key trends taking place. All this data from previous years are stored in a database warehouse. Since the data stored has gone through all kinds of screening, editing and integration it does not need any further editing or alteration.
With this database ensure that the software requirements specification (SRS) is formally approved as part of the project quality plan.
4.0 Distributed Databases
Many organisations have several office locations, manufacturing plants, regional offices, branch offices and a head office at different geographic locations. Each of these work groups may have their own database which together will form the main database of the company. This is known as a distributed database.
5.0 End-User Databases
There is a variety of data available at the workstation of all the end users of any organisation. Each workstation is like a small database in itself which includes data in spreadsheets, presentations, word files, note pads and downloaded files. All such small databases form a different type of database called the end-user database.
6.0 External Database
There is a sea of information available outside world which is required by an organisation. They are privately-owned data for which one can have conditional and limited access for a fortune. This data is meant for commercial usage. All such databases outside the organisation which are of use and limited access are together called external database.
7.0 Hypermedia Database
Most websites have various interconnected multimedia pages which might include text, video clips, audio clips, photographs and graphics. These all need to be stored and “called” from somewhere when the webpage if created. All of them together form the hypermedia database.
Please note that if you are creating such a database from scratch to be generous when creating a project plan, detailed when defining the business requirements documentation (BRD) and meticulous in your project cost controls. I have seen too many projects where the creation of one of these databases has caused scope creep and an out of control budget for a project.
8.0 Navigational Database
Navigational database has all the items which are references from other objects. In this, one has to navigate from one reference to other or one object to other. It might be using modern systems like XPath. One of its applications is the air flight management systems.
9.0 In-Memory Database
An in-memory databases stores data in a computer’s main memory instead of using a disk-based storage system. It is faster and more reliable than that in a disk. They find their application in telecommunications network equipments.
10.0 Document-Oriented Database
A document oriented database is a different type of database which is used in applications which are document oriented. The data is stored in the form of text records instead of being stored in a data table as usually happens.
11.0 Real-Time Database
A real-time database handles data which constantly keep on changing. An example of this is a stock market database where the value of shares change every minute and need to be updated in the real-time database. This type of database is also used in medical and scientific analysis, banking, accounting, process control, reservation systems etc. Essentially anything which requires access to fast moving and constantly changing information.
Assume that this will require much more time than a normal relational database when it comes to the software testing life cycle, as these are much more complicated to efficiently test within normal timeframes.
12.0 Analytical Database
An analytical database is used to store information from different types of databases such as selected operational databases and external databases. Other names given to analytical databases are information databases, management databases or multi-dimensional databases. The data stored in an analytical database is used by the management for analysis purposes, hence the name. The data in an analytical database cannot be changed or manipulated.
Different Types of Databases Top 12 - Tip
Of the different types of databases, relational is the most common and includes such well known names as Oracle, Sybase and SQL Server. However as a project manager you need to be prepared for anything, hence why having a high level view of the different databases is useful particularly when managing a software development life cycle. Regarding the remainder, you will hear a great deal about database warehouses. This is a highly specialised area which involves mining the data produced to generate meaningful trends and reports for senior management to act upon.
source
http://www.my-project-management-expert.com/different-types-of-databases.html
http://www.my-project-management-expert.com/different-types-of-databases-2.html
Relational Databases :
In relational databases, the relationship between data files is relational. Hierarchical and network databases require the user to pass a hierarchy in order to access needed data. These databases connect to the data in different files by using common data numbers or a key field. Data in relational databases is stored in different access control tables, each having a key field that mainly identifies each row. In the relational databases are more reliable than either the hierarchical or network database structures. In relational databases, tables or files filled up with data are called relations (tuples) designates a row or record, and columns are referred to as attributes or fields.
Relational databases work on each table has a key field that uniquely indicates each row, and that these key fields can be used to connect one table of data to another.

The relational database has two major reasons:
- Relational databases can be used with little or no training.
- Database entries can be modified without specify the entire body.
Properties of Relational Tables:
In the relational database we have to follow some properties which are given below.
- It's Values are Atomic
- In Each Row is alone.
- Column Values are of the Same thing.
- Columns is undistinguished.
- Sequence of Rows is Insignificant.
- Each Column has a common Name.
source
http://www.c-sharpcorner.com/uploadfile/65fc13/types-of-database-management-systems/
Data VS information
What is data?
Data can be defined as a representation of facts, concepts or instructions in a formalized manner which should be suitable for communication, interpretation, or processing by human or electronic machine.
Data is represented with the help of characters like alphabets (A-Z,a-z), digits (0-9) or special characters(+,-,/,*,<,>,= etc.).
Data is the raw material that is to be processed for information or for collection of details. It is unorganized data or facts that are to be processed. Data is plain fact and it has to be processed for further information. Data is alone enough to get details and find the meaning of something. Data is the computers language. Data is useless unless it is processed or has been made into something. Data has no meaning when it has not been interpreted. Data is an unclear definition of words jumbled up to form one meaning of something. Data comes in figures, dates and numbers and is not processed.
Examples of Data
- Student Data on Admission Forms: When students get admission in a college. They fill admission form. This form contains raw facts (data of student) like name, father’s name, address of student etc.
- Data of Citizens: During census, data of all citizens is collected.
- Survey Data: Different companies collect data by survey to know the opinion of people about their product.
- Students Examination data: In examination data about obtained marks of different subjects for all students is collected.
Data Processing Cycle
Data processing is the re-structuring or re-ordering of data by people or machine to increase their usefulness and add values for particular purpose. Data processing consists of basic steps input, processing and output. These three steps constitute the data processing cycle.
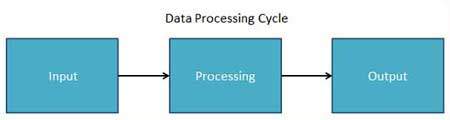
-
Input - In this step the input data is prepared in some convenient form for processing. The form will depend on the processing machine. For example, when electronic computers are used, the input data could be recorded on any one of several types of input medium, such as magnetic disks, tapes and so on.
-
Processing - In this step input data is changed to produce data in a more useful form. For example, pay-checks may be calculated from the time cards, or a summary of sales for the month may be calculated from the sales orders.
-
Output - Here the result of the proceeding processing step are collected. The particular form of the output data depends on the use of the data. For example, output data may be pay-checks for employees.
-
What is Information?
Information is organised or classified data which has some meaningful values for the receiver.
Information is the processed data on which decisions and actions are based.
For the decision to be meaningful, the processed data must qualify for the following characteristics:
-
Timely - Information should be available when required.
-
Accuracy - Information should be accurate.
-
Completeness - Information should be complete.
Information
Information is processed data. The data that can be made useful is known as information. Information is basically the data plus the meaning of what the data was collected for. Data does not depend upon information but information depends upon data. It cannot be generated without the help of data. Information is something that is being conveyed. Information is meaningful when data is gathered and meaning is generated. Information cannot be generated without the help of data. Information is the meaning that has been formed with the help of data and that meaning makes sense because of the data that has been collected against the word. Information is processed and comes in a meaningful form.
Examples of Information
- Student Address Labels: Stored data of students can be used to print address labels of students.
- Census Report: Census data is used to get report/information about total population of a country and literacy rate etc.
- Survey Reports and Results: Survey data is summarized into reports/information to present to management of the company.
- Result Cards of Individual Students: In examination system collected data (obtained marks in each subject) is processed to get total obtained marks of a student. Total obtained marks are Information. It is also used to prepare result card of a student.
- Merit List: After collecting admission forms from candidates, merit is calculated on the basis of obtained marks of each candidate. Normally, percentage of marks obtained is calculated for each candidate. Now all the candidates names are arranged in descending order by percentage. This makes a merit list. Merit list is used to decide whether a candidate will get admission in the college or not.
-
Comparison Chart
Basis of Distinction Data Information Definition Data are raw numbers or other findings which, by themselves, are of limited value. Information is data that has been converted into a meaningful and useful context. Example Ticket sales on a band on tour. Sales report by region and venue – tells us which venue is most profitable. Significance Data by itself alone is not significant. Information is significant by itself. Etymology Data is a plural of datum, which is originally a Latin noun meaning “something given.” Its origin dates back to the 1600s. Its origin dates back to the 1300s.
Key Differences
- Data is the input language for a computer and information is the output language for human.
- Data is unprocessed facts or mere figures but information is processed data which has been made sense of.
- Data does not depend on information but information depends on data and without it, information cannot be processed.
- Data is not specific but information is specific enough to generate meaning.
- Data is the raw material that is collected but information is a detailed meaning generated from the data.
source
https://www.tutorialspoint.com/computer_fundamentals/computer_data.htm
http://www.differencebtw.com/difference-between-data-and-information/